파이썬 3.13 으로 통일함.
github 프로젝트에서 브랜치를 만들어 코딩 진행할 것.
vscode 에서 commit 할 때 기능번호(예: #53)를 먼저 쓰고 제목 쓸 것.

청년 정책 챗봇 데이터 수집 파이프라인 설계
1. 개요
청년 정책 안내 챗봇을 위한 데이터 수집 파이프라인을 설계합니다. API와 사용자 수동 업로드를 통해 데이터를 수집하고, RAG (Retrieval Augmented Generation) 모델에 활용하기 위한 형태로 가공 및 저장합니다.
2. 요구사항
- 데이터 소스:
- API (JSON)
- 수동 업로드 (PDF, 일반 공고문 사이즈)
- 수집 주기: 매주 배치 처리
- 저장소: Amazon S3
- 데이터 처리: AWS Lambda
- 임베딩 DB: PostgreSQL
- RAG 모델: PostgreSQL에 접근하여 데이터 활용
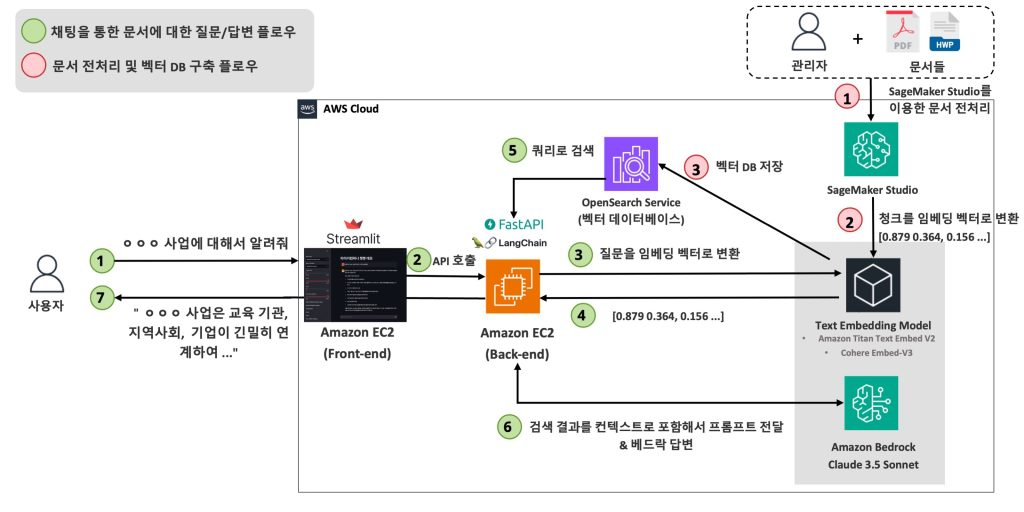
3. 아키텍처 다이어그램

https://www.aimag.in/ai/architecture-of-ai-chatbot/

멘토링 250520,
피드백,
기획서,
- 정부 정책 예산 :3조 / 전체 600조 -> 0.5%,
- 청년 인구 : 1000만명 -> 1인당 30만원,
- 청년 정책 파편화되어 있음. : 정보 주체화,
- 나이 구간 설정도 천차만별하다.,
- value proposition? : 10배 정도 받을 수 있게 도와줄게. > 수익 극대화해줄게..,
화면설계서 (mock up),
- 일단 단순하게라도 시작해서 늘려가면 된다.,
- 잘 만들었다!,
데이터 테이블 설계,
- (faq_id > help_id),
-
- 훨씬 더 정확해진다.
- 숫자가 들어가면 KAG 가 더 낫다.,프롬프트에 kag 관련 내용을 한 줄 더 추가
- kag (지식 표현) : 그래프 디비
-
- 데이터 전처리 방안 고민하기.,
ML,
- 정책을 분류, 군집하여 한 장으로 표현,
- 나이별로 정책 모음 및 개수 시각화,
- 정책 대분류, 중분류, 소분류 등으로 나눠서 시각화,
- scikit learn - 공식대로 따라가면 된다.,
https://scikit-learn.org/1.4/tutorial/machine_learning_map/index.html
llm 모델 정량적 평가 기준,
- 사실 평가하기 어렵다,
- 정량적,정성적 평가,
- 사람에 따른 조건이 다 다르다
- 휴먼 피드백을 얻을 받을 수 밖에 없다.,
- voting 시스템,
- 강화 학습,
- 사람에 따른 조건이 다 다르다
-
- 평점 시스템,정성적 :
- accuracy를 맞출 순 있을거다.,
- 모델 비교 평가해서 선택,
기업 채용,
- 600개 대기업,
- 피라미드식으로 밑에서 부터 2-3번 이직하면 올라가게 되어 있다.,
- 근속년수 2~5년 밖에 안된다...,
- 클라우드 과장급 이상 많이 뽑는다...,
- 2000개 상장기업에서 직원은 150만명 -> 7% 는 대기업...?!,
앞으로 할 일,
- 데이터 수집,
- EDA > Field Engineering 반복,
- 시각화,
- 모델 학습,
- 성능 평가,
중간발표,
- 발표자: 이유호,
- 뼈대는 완성함,
- 사진 중요하다 - 지브리풍 사진,
더닝 크루거 효과,
- 프로젝트 하면서 겪음.
https://discuss.pytorch.kr/t/kag-knowledge-augmented-generation-feat-ant-group/5791
KAG(Knowledge-Augmented Generation): 논리적 추론 및 정보 검색 프레임워크 (feat. Ant Group)
KAG 소개 KAG(Knowledge Augmented Generation)는 도메인 지식 기반의 논리적 추론(Logical Reasoning) 및 질문-답변(Q&A)을 위한 프레임워크입니다. 특히, 기존의 RAG(Vector 기반 검색, Retrieval-Augmented Generation)나 Graph
discuss.pytorch.kr


정량적 평가 지표 (Quantitative Metrics)
- 정답률 (Accuracy) 또는 정답 일치율 (Exact Match),
적용 예시: 사용자가 "청년 월세 지원 있나요?"라고 물었을 때, 챗봇이 정확히 관련 정책을 언급했는지 평가. 방법: 사전에 정답 정책을 정해두고, LLM의 응답이 그와 일치하는지 자동 비교.
- 정답 유사도 지표 (F1-score, ROUGE, BERTScore),
완벽히 일치하지 않아도 핵심 정보(정책명, 지원 요건 등)를 포함하면 정답으로 인정하는 평가 방식. BERTScore는 의미 기반 유사도까지 측정 가능해 정책 응답에서 유리함.
- 검색 적중률 (Top-k Retrieval Accuracy),
RAG 기반 챗봇일 경우, 벡터 검색이 관련 문서를 잘 찾아냈는지를 평가. 예: 사용자 질문과 가장 관련 있는 문서를 상위 3개 내에 포함시켰는가?
- 응답 속도,
정책 정보를 얼마나 빠르게 제공하는가. 실제 서비스 품질을 위한 운영 지표로 활용.

정성적 평가 지표 (Qualitative Metrics)
- 정답성(Factual Correctness),
챗봇이 실제 정책 내용과 다른 정보를 말하지 않는가? 정책명, 나이/소득 기준, 지원 금액 등이 정확한가? 사람 평가자 또는 정책 담당자가 확인.
- 관련성(Relevance),
사용자의 질문과 챗봇의 응답이 얼마나 관련이 있는가? 예: 주거 정책 질문에 창업 정책을 답하지 않았는가?
- 맞춤형 응답 적절성 (Personalization Quality),
사용자의 정보(나이, 거주지 등)를 기반으로 한 맞춤형 정책 추천이 적절했는가? 예시 평가 방법: "사용자 프로필 A → 추천 정책 X" 도메인 전문가가 매칭 결과 평가
- 자연스러움(Fluency) & 일관성(Coherence),
문장이 부자연스럽거나 앞뒤 맥락이 어긋나지 않았는가? 긴 대화에서 맥락을 잘 이어가는가?
- 유용성(Helpfulness),
사용자가 "정책 정보를 잘 이해할 수 있었는가?" 방법: 사용자 설문 또는 5점 척도 평가
- 이탈률 / 재질문률 (실사용 기준),
사용자가 정책 설명을 듣고 다시 묻거나 이탈하는 비율. "정책을 더 간단히 말해줘", "무슨 말인지 모르겠어요" 등도 유의미한 지표

요약표 평가 항목 지표/방법 유형 정책 응답 정확도 Accuracy, F1-score, Exact Match 정량적 유사도 기반 평가 BERTScore, ROUGE 정량적 검색 성능 Top-k Recall (검색 문서 적중률) 정량적 정답성 정책과 사실 일치 여부 (사람 평가자) 정성적 관련성 질문과 응답의 적합도 정성적 개인화 적절성 맞춤형 추천의 정확도 정성적 문장 자연스러움 Fluency 평가 (5점 척도) 정성적 대화 일관성 이전 발화와의 연결성 정성적 사용자 만족도 만족도 설문 (예: 도움됨 1~5점) 정성적 이탈/재질문률 로그 분석 기반 지표 정량/정성 혼합 필요하다면 실제 평가 양식 예시(Excel or JSON 형식)나 모의 평가 시나리오도 만들어드릴 수 있습니다.